不用部署Whisper服务 笔记本本地就能跑的实时语音转写方案
很多AI从业者做语音转写的第一选择是部署Whisper服务,不仅要占用服务器资源,还需要传输音频数据存在隐私风险。现在Liquid AI的LFM2-Audio-1.5B可配合llama.cpp在普通笔记本本地实时运行,全程无需联网,数据无外泄风险,附完整操作步骤和拓展用法。
工程师Pau Labarta Bajo最近分享了一个给AI从业者的实用建议:做语音转写,不用非得在服务器上部署Whisper。
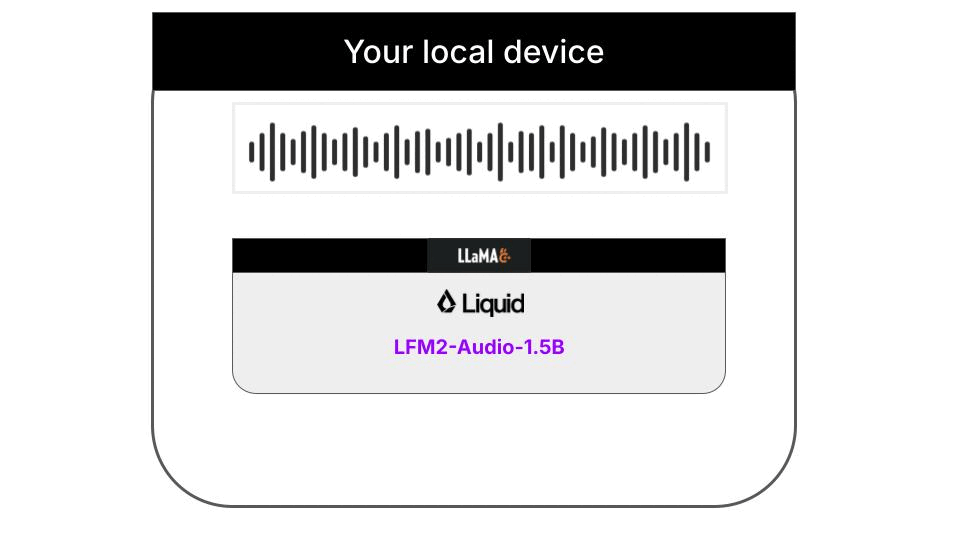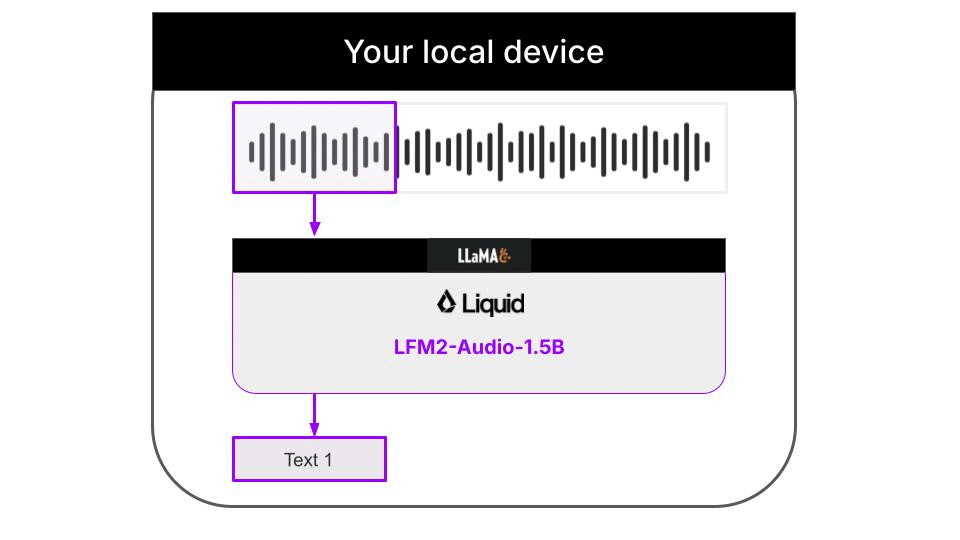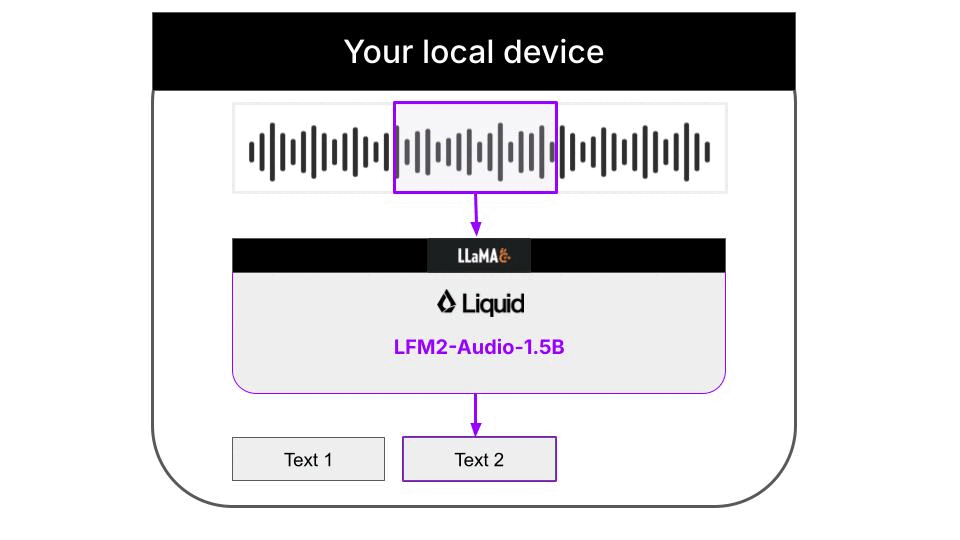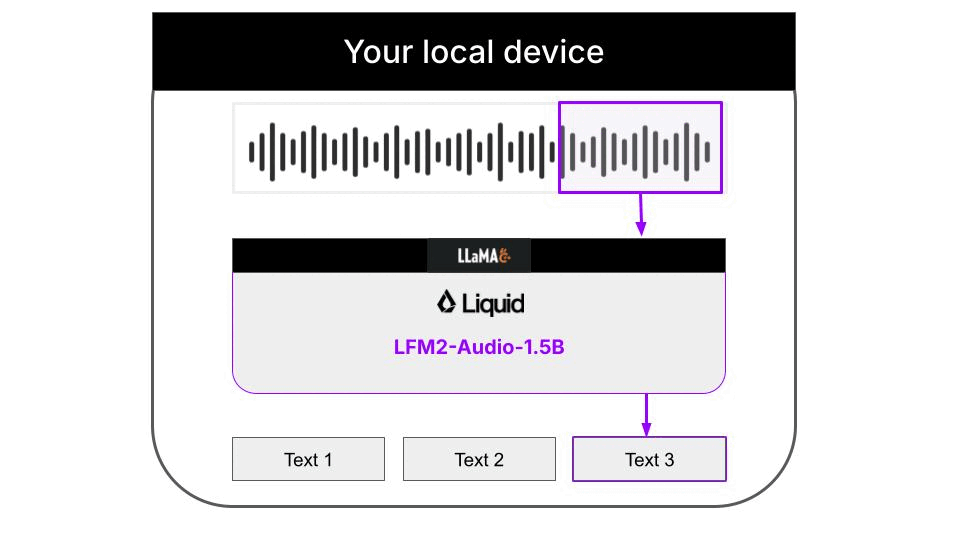
Liquid AI推出的LFM2-Audio-1.5B模型,配合llama.cpp推理框架,就能在普通笔记本上实现实时语音转写,全程不需要联网,所有音频和转写结果都只存在本地,不会上传到任何服务器。整个流程的架构如下:
### 快速上手步骤
整个方案的配置过程不需要手动编译依赖,官方已经做好了自动化脚本,按照以下四步操作即可:
1. 克隆官方示例仓库
```
git clone https://github.com/Liquid4All/cookbook.git
cd cookbook/examples/audio-transcription-cli
```
2. 安装包管理工具uv(如果系统里已经有可以跳过)
**macOS/Linux:**
```
curl -LsSf https://astral.sh/uv/install.sh | sh
```
**Windows:**
```
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
```
3. 下载测试用音频样本
```
uv run download_audio_samples.py
```
4. 运行转写命令,就能在控制台看到实时转写结果,加上`--play-audio`参数可以同步播放音频
```
uv run transcribe --audio './audio-samples/barackobamafederalplaza.mp3' --play-audio
```
### 支持平台
目前官方编译好的适配包支持四类平台:
- android-arm64
- macos-arm64
- ubuntu-arm64
- ubuntu-x64
其他平台的用户需要等待官方后续更新适配包。
### 拓展用法
这个方案底层用的llama.cpp是用C++编写的开源轻量推理框架,比常用的PyTorch、transformers库运行效率高很多,适合端侧部署。整个CLI会自动下载对应平台的适配版llama.cpp,不需要用户手动处理编译问题。
除了基础的语音转写(ASR),LFM2-Audio-1.5B还支持文本转语音(TTS),甚至可以自定义语音风格,官方给出了三个核心场景的命令行示例:
1. 语音转写
```
# Audio to Speech Recognition (ASR)
./llama-lfm2-audio \
-m $CKPT/LFM2-Audio-1.5B-Q8_0.gguf \
--mmproj $CKPT/mmproj-audioencoder-LFM2-Audio-1.5B-Q8_0.gguf \
-mv $CKPT/audiodecoder-LFM2-Audio-1.5B-Q8_0.gguf \
-sys "Perform ASR." \
--audio $INPUT_WAV
```
2. 基础文本转语音
```
# Text To Speech (TTS)
./llama-lfm2-audio \
-m $CKPT/LFM2-Audio-1.5B-Q8_0.gguf \
--mmproj $CKPT/mmproj-audioencoder-LFM2-Audio-1.5B-Q8_0.gguf \
-mv $CKPT/audiodecoder-LFM2-Audio-1.5B-Q8_0.gguf \
-sys "Perform TTS." \
-p "My name is Pau Labarta Bajo and I love AI" \
--output $OUTPUT_WAV
```
3. 自定义风格的文本转语音
```
./llama-lfm2-audio \
-m $CKPT/LFM2-Audio-1.5B-Q8_0.gguf \
--mmproj $CKPT/mmproj-audioencoder-LFM2-Audio-1.5B-Q8_0.gguf \
-mv $CKPT/audiodecoder-LFM2-Audio-1.5B-Q8_0.gguf \
-sys "Perform TTS.
Use the following voice: A male speaker delivers a very expressive and animated speech, with a low-pitch voice and a slightly close-sounding tone. The recording carries a slight background noise." \
-p "What is your name man?" \
--output $OUTPUT_WAV
```
### 优化方案
目前直接输出的转写文本,因为音频分片重叠的问题,可能会出现断句错误、语法不通的情况。官方给出了本地优化方案:搭配同系列的LFM2-350M小尺寸文本模型做后处理清洗,两步本地 workflow 就能大幅提升转写质量,全程依然不需要联网。
完整的官方文档和最新更新可以查看:[实时音频转写官方文档](https://docs.liquid.ai/examples/laptop-examples/audio-to-text-in-real-time)
发布时间: 2026-05-23 00:01