LoRA微调模型推理提速1.5倍:我们如何解决PEFT服务的性能瓶颈
Databricks团队通过定制化推理引擎,在保持模型质量的同时,将LoRA微调模型的推理吞吐量提升至开源引擎的1.5倍。关键在于量化策略、内核重叠和流式多处理器分区等技术创新。

微调模型(特别是LoRA)能显著提升质量,但推理服务一直是个挑战。开源方案在真实场景下性能可能下降60%,而我们的定制推理引擎实现了1.5倍的吞吐量提升。
## 问题本质
LoRA推理的核心矛盾在于:为了保持质量,需要较高的秩(如32),但这会导致矩阵乘法维度不均衡。传统优化针对大模型设计,对LoRA的小规模计算效率低下。
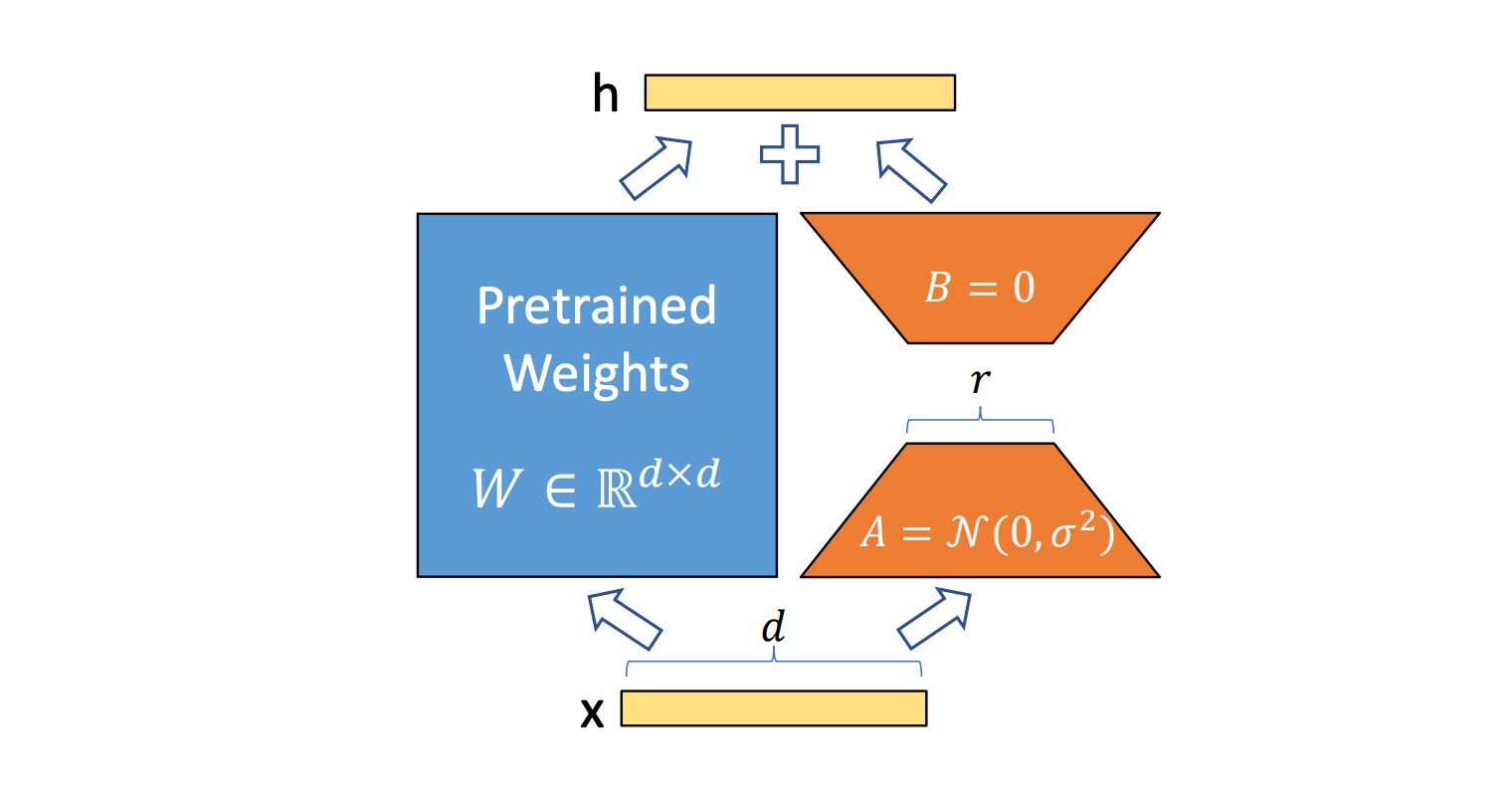
*图:LoRA推理中的计算路径,橙色部分为额外开销*
## 量化不损质量
大多数框架在FP8量化时面临两难:全FP8计算快但损失精度,BF16准确但速度慢。我们采用混合注意力机制——QK计算在FP8完成,PV计算在BF16进行,通过warp specialization技术隐藏转换开销。
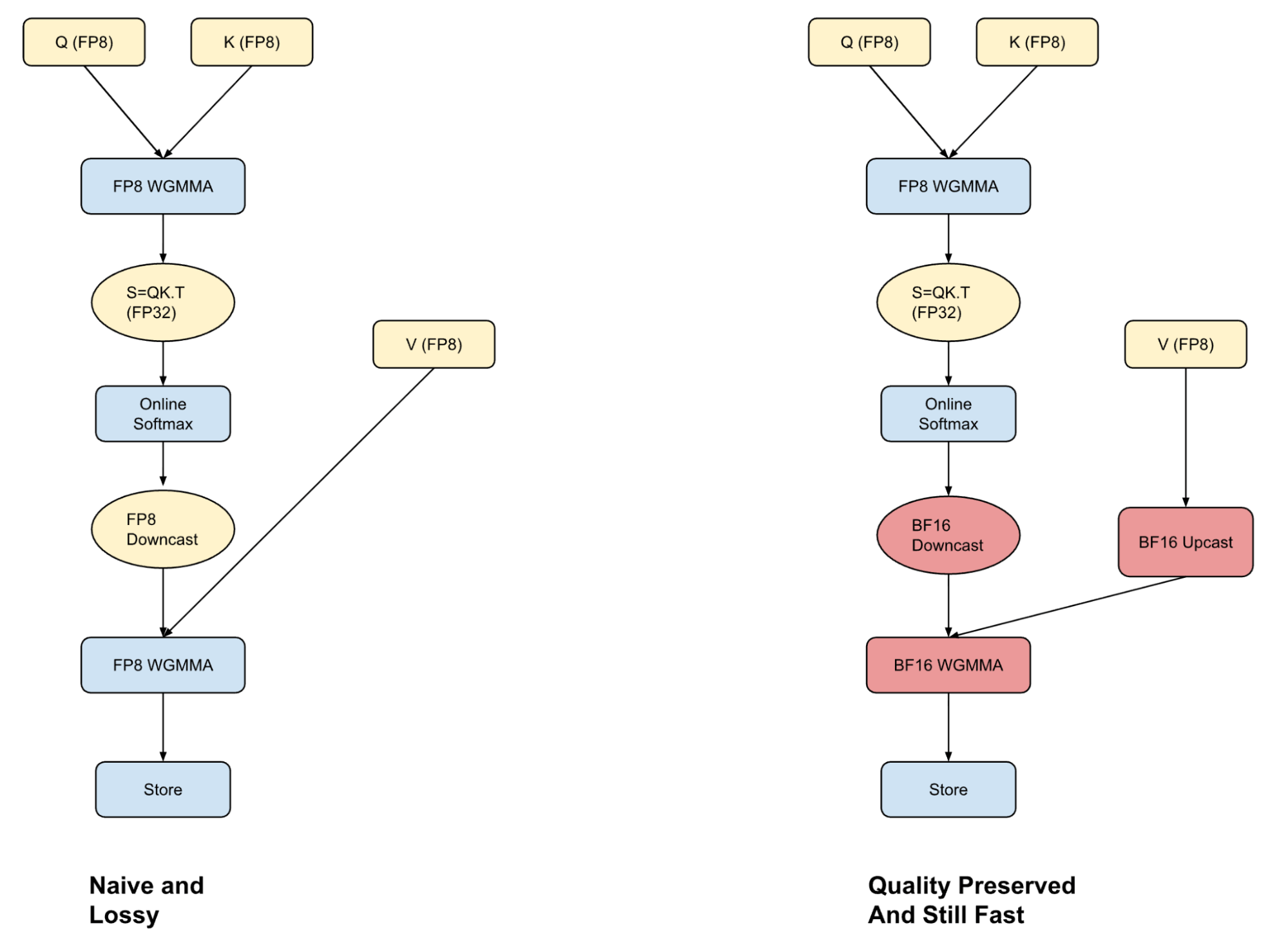
*图:混合注意力机制在速度和精度间取得平衡*
更关键的是行级FP8量化。相比张量级量化,行级缩放因子虽然增加计算量,但通过内核融合技术,这些开销几乎被完全隐藏。
## 内核重叠技术
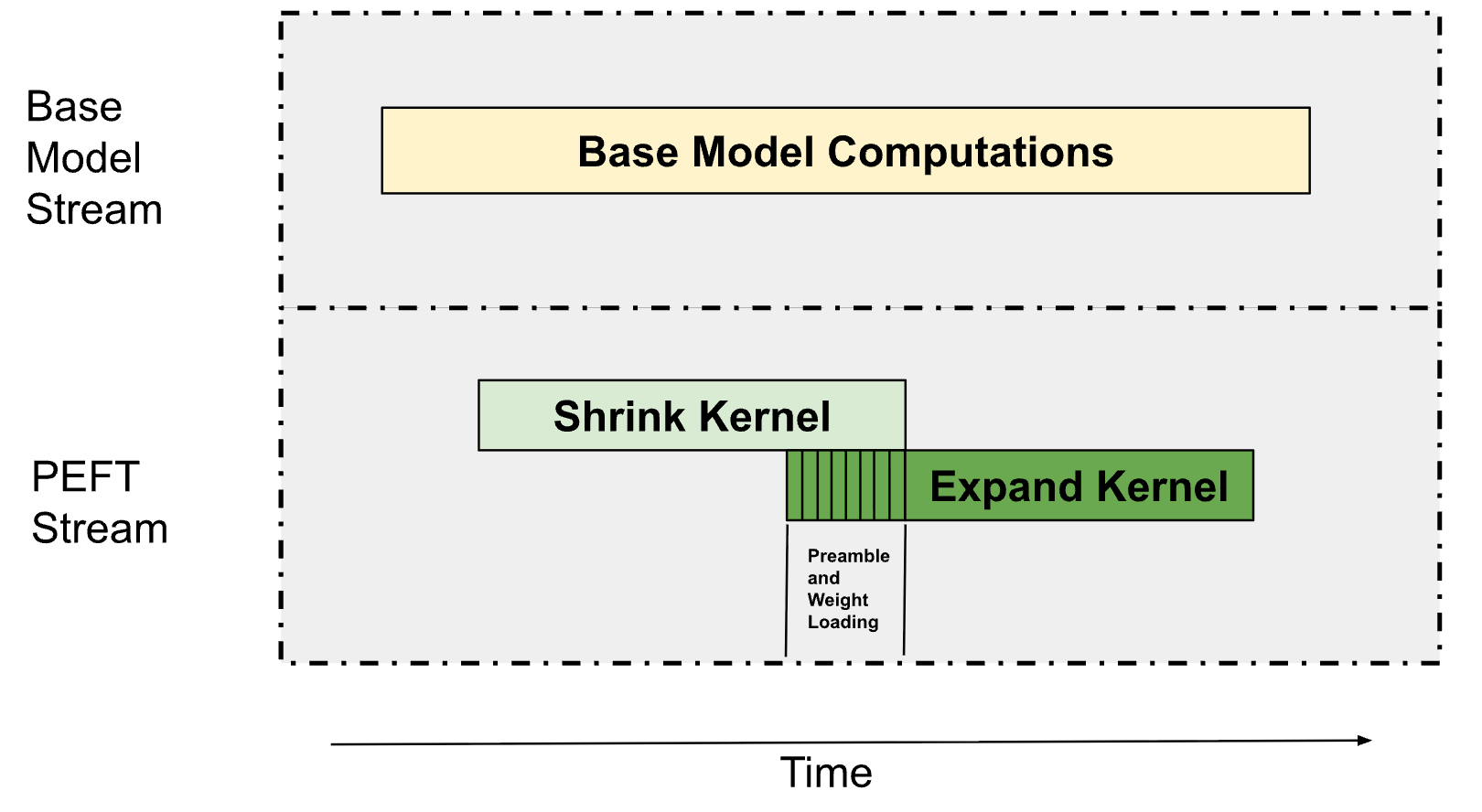
*图:通过流分区和PDL技术实现计算重叠*
LoRA推理包含收缩核和扩展核两个主要操作。我们采用两项关键技术:
1. **多处理器分区**:基础模型占用75%的SM,PEFT路径使用剩余资源。带宽密集型操作不需要全部SM即可达到峰值内存带宽。
2. **程序化依赖启动**:在收缩核执行时预取扩展核权重,通过资源限制确保两个内核能并行执行。
## 性能对比
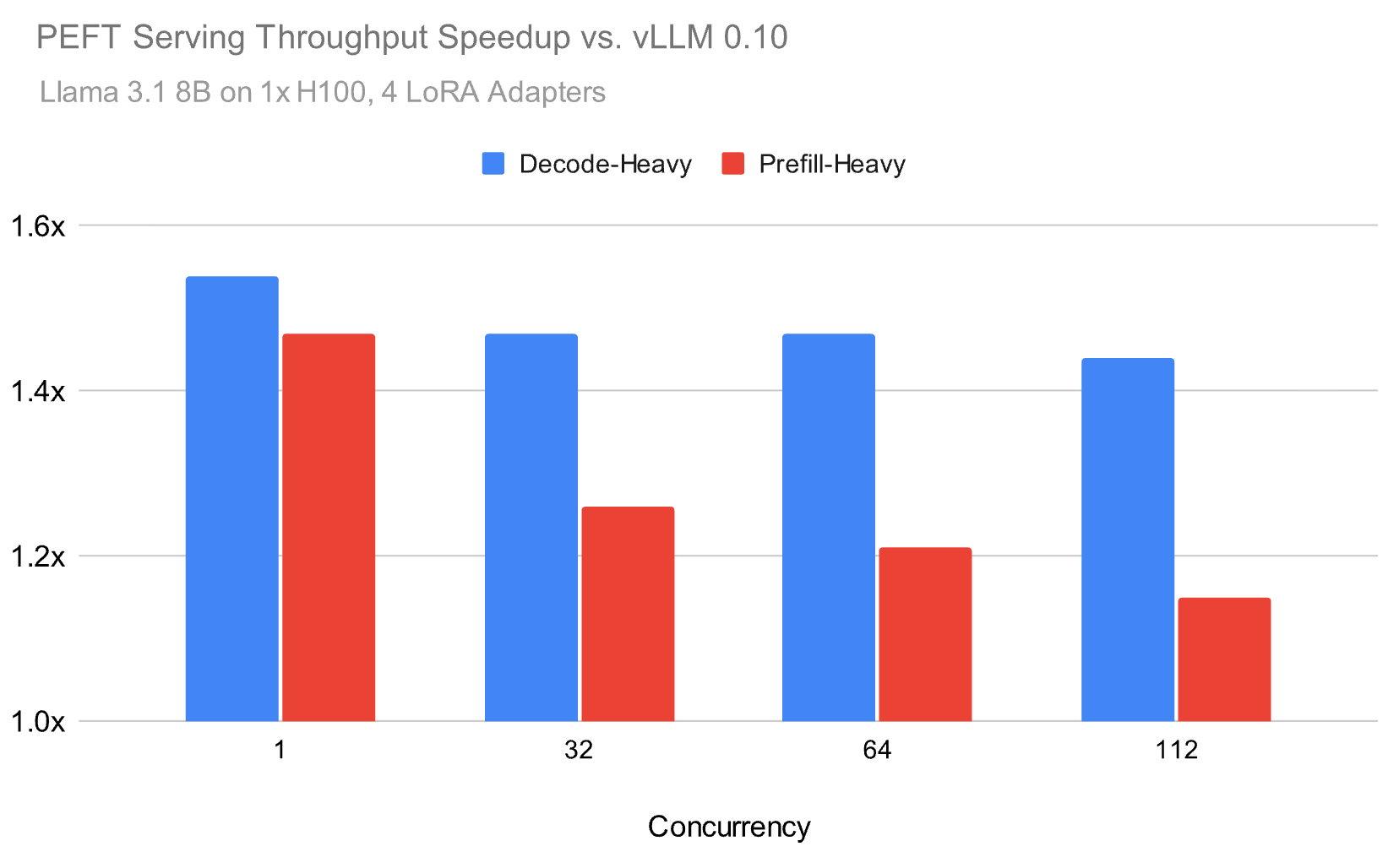
*图:在不同并发量下的吞吐量表现*
在Llama 3.1 8B模型上,平均加载4个LoRA适配器时,我们的方案在解码密集型工作负载上保持1.5倍优势,即使在高并发下仍显著领先。
更重要的是质量保持。在HumanEval和数学推理基准测试中,我们的量化方案几乎与全精度BF16结果一致,而vLLM等开源方案出现明显质量下降。
## 技术启示
这个案例说明,优化不能只盯着局部性能。真正的突破来自系统级思考:如何让量化、调度、内存管理协同工作。
对于需要服务多个专业模型的场景,这些优化意味着更低的成本和更高的响应速度。现在,企业可以用更少的资源部署更多定制化AI应用。
推理优化的竞争才刚刚开始,但方向很明确:未来的赢家不是最快的内核,而是最智能的系统。
发布时间: 2025-10-22 06:21