1.5x Faster Inference for LoRA Fine-Tuned Models: How We Solved PEFT Service Performance Bottlenecks
The Databricks team achieved a 1.5x increase in inference throughput for LoRA fine-tuned models while maintaining model quality by customizing the inference engine. The key lies in innovations like quantization strategies, kernel overlap, and streamed multi-processor partitioning.

Fine-tuned models (especially LoRA) can significantly improve quality, but inference services have always been a challenge. Open-source solutions may degrade performance by 60% in real-world scenarios, while our custom inference engine delivers a 1.5x throughput improvement.
## The Core Problem
The core contradiction in LoRA inference is: to maintain quality, higher ranks (e.g., 32) are needed, which leads to unbalanced matrix multiplication dimensions. Traditional optimizations are designed for large models and are inefficient for LoRA's small-scale computations.
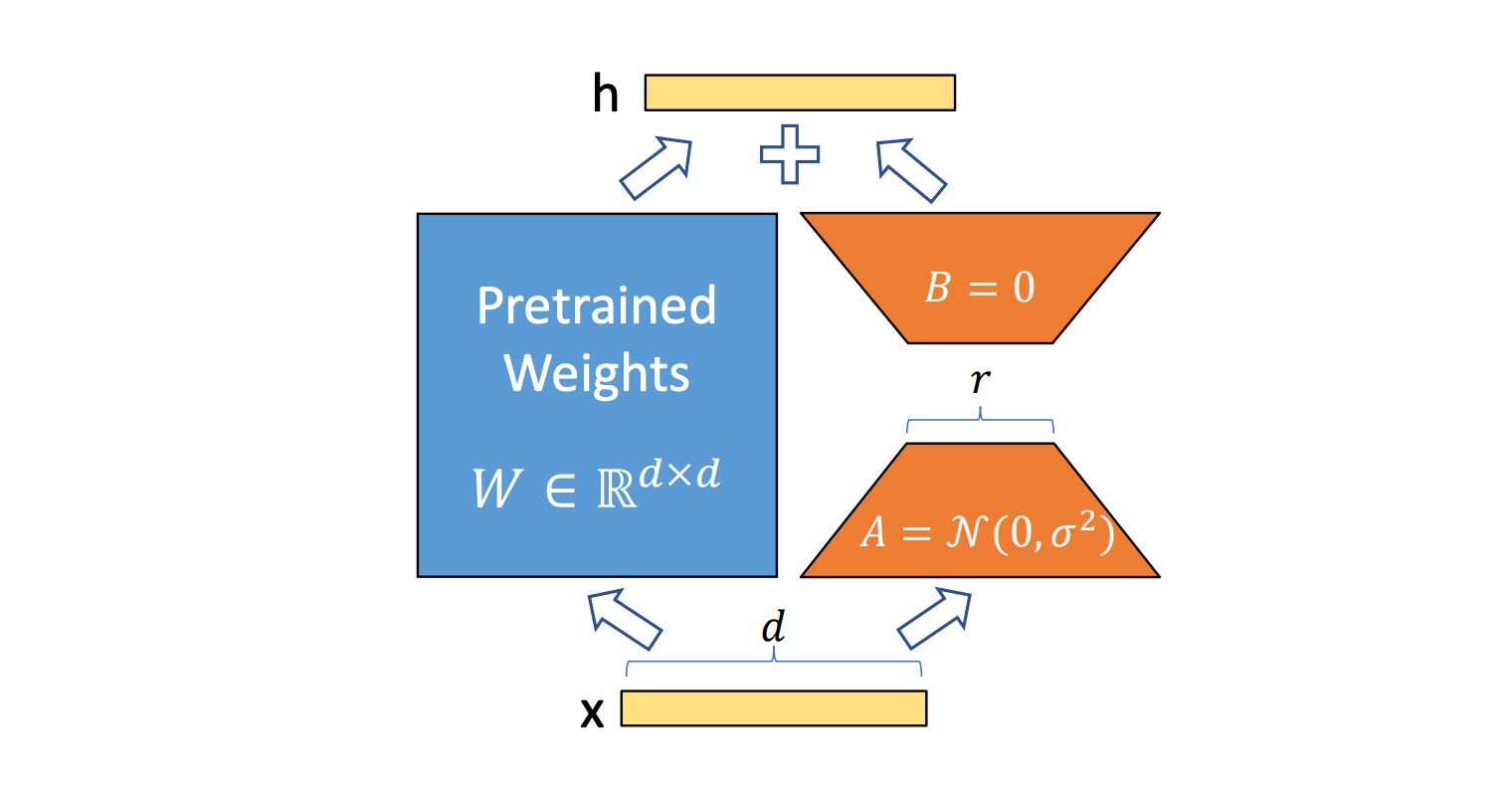
*Figure: Computational paths in LoRA inference, with orange highlighting additional overhead*
## Quantization Without Quality Loss
Most frameworks face a dilemma when using FP8 quantization: full FP8 computation is fast but sacrifices precision, while BF16 is accurate but slow. We employ a hybrid attention mechanism—QK computation in FP8, PV computation in BF16—hiding the conversion overhead through warp specialization technology.
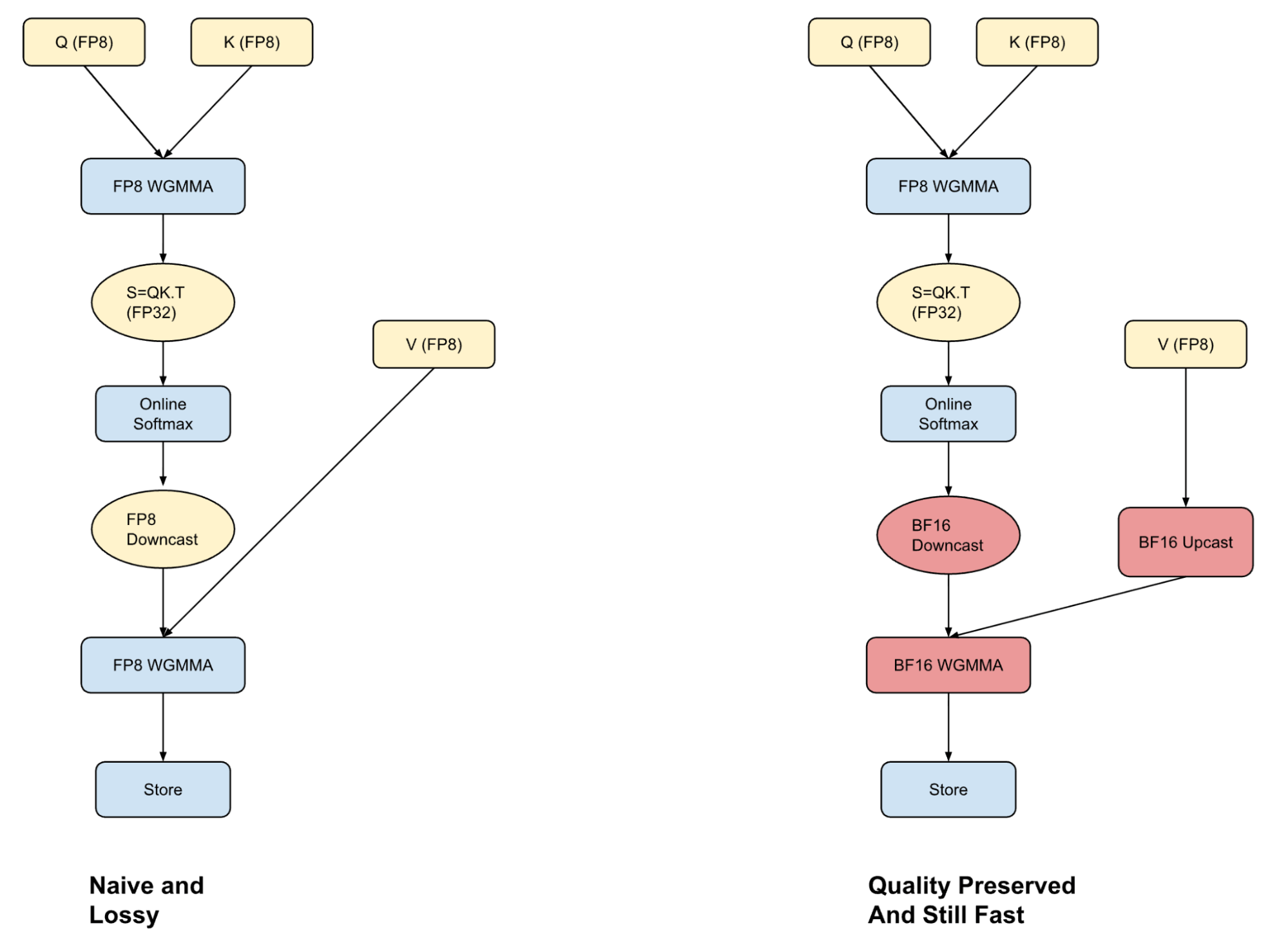
*Figure: Hybrid attention mechanism balances speed and precision*
More critically, row-level FP8 quantization. Compared to tensor-level quantization, row-level scaling factors increase computation but are nearly entirely hidden through kernel fusion techniques.
## Kernel Overlap Techniques
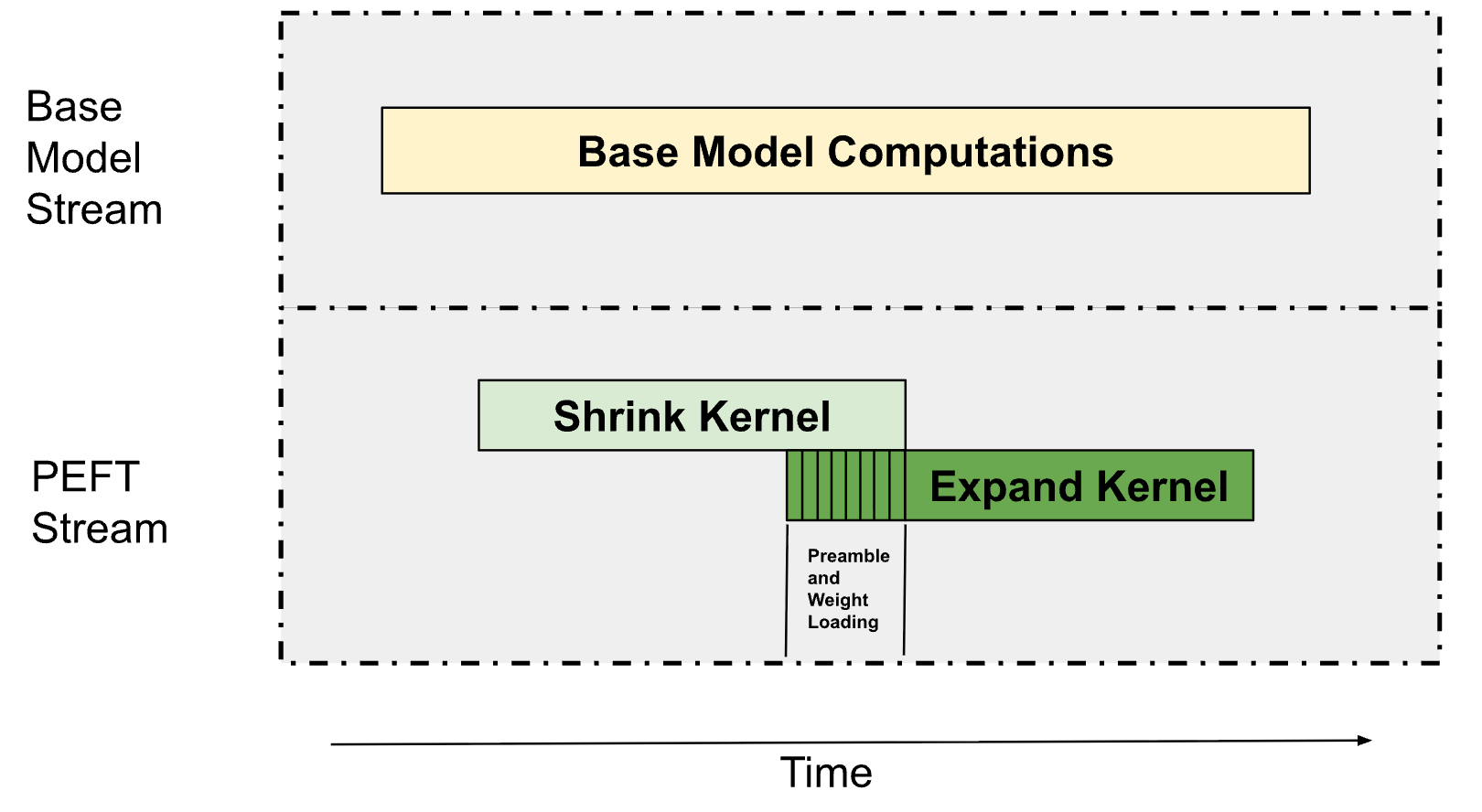
*Figure: Computational overlap achieved through streamed partitioning and PDL techniques*
LoRA inference consists of two main operations: contraction kernels and expansion kernels. We use two key techniques:
1. **Multi-processor partitioning**: The base model occupies 75% of the SM, while the PEFT path uses remaining resources. Bandwidth-intensive operations don't require full SMs to achieve peak memory bandwidth.
2. **Programmatic dependency initiation**: Pre-fetch expansion kernel weights during contraction kernel execution, ensuring parallel execution through resource constraints.
## Performance Comparison
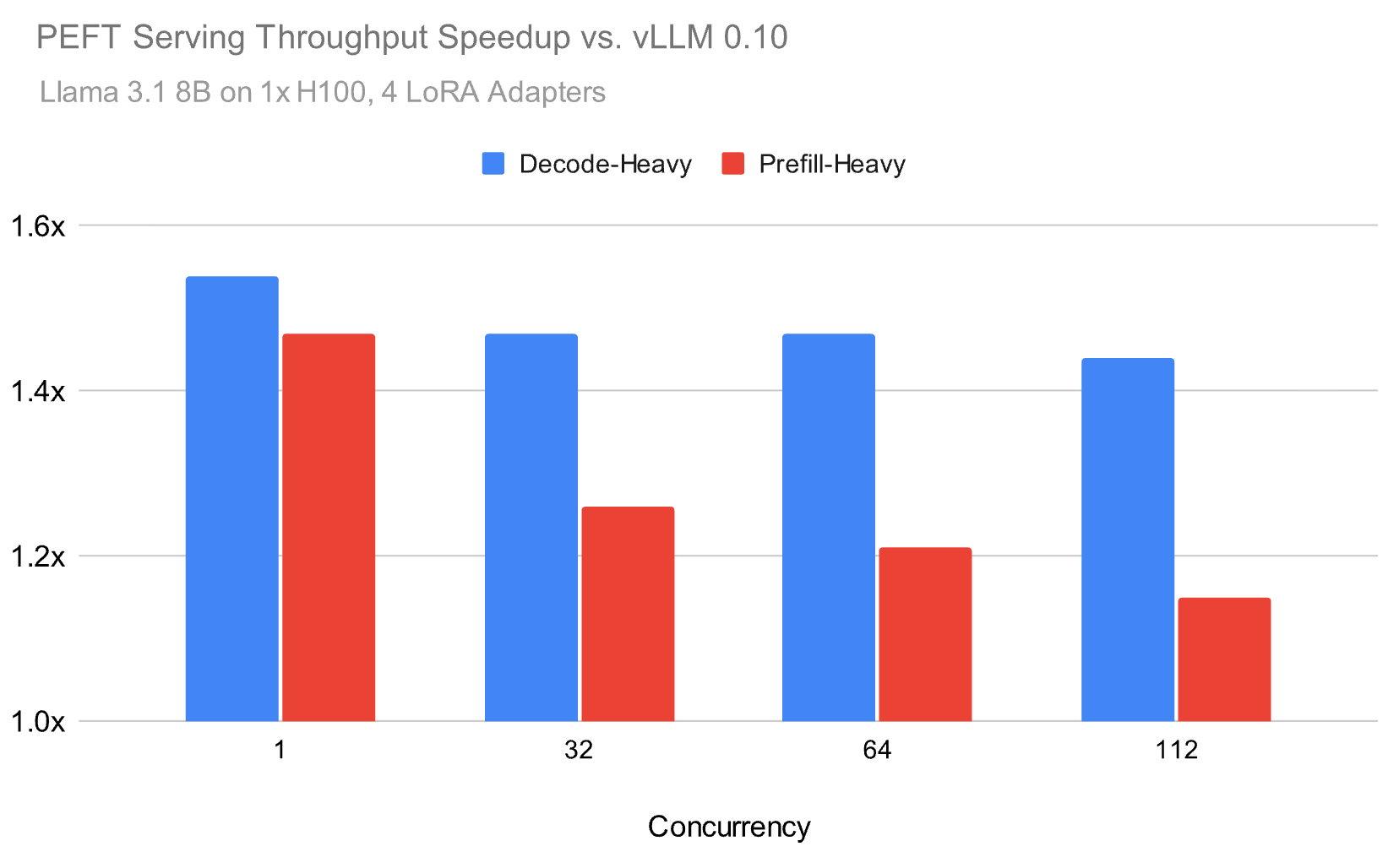
*Figure: Throughput performance under different concurrency levels*
On the Llama 3.1 8B model, with an average of 4 LoRA adapters loaded, our solution maintains a 1.5x advantage in decode-intensive workloads, even under high concurrency. More importantly, quality is preserved. Our quantization scheme matches full-precision BF16 results nearly identically in HumanEval and math reasoning benchmarks, while open-source solutions like vLLM show significant quality degradation.
## Technical Insights
This case demonstrates that optimization shouldn't just focus on local performance. True breakthroughs come from systems-level thinking: how to make quantization, scheduling, and memory management work together.
For scenarios serving multiple specialized models, these optimizations mean lower costs and faster response times. Now, enterprises can deploy more customized AI applications with fewer resources.
The race in inference optimization is just beginning, but the direction is clear: future winners won't be the fastest kernels, but the smartest systems.
发布时间: 2025-10-22 06:21